准备知识
同步和异步
同步和异步其实指的是,请求发起方对消息结果的获取是主动发起的还是等被动通知的。如果是请求方主动发起的,一直在等待应答结果(同步阻塞),或者可以先去处理其他的事情,但要不断轮询查看发起的请求是否有应答结果(同步非阻塞),因为不管如何都要发起方主动获取消息结果,所以形式上还是同步操作。如果是由服务方通知的,也就是请求方发出请求后,要么在一直等待通知(异步阻塞),要么就先去干自己的事情(异步非阻塞),当请求处理完成之后,服务方会主动通知请求方,这就是异步。异步通知的方式一般是通过状态改变、消息通知或者回调函数来完成,大多数时候采用的都是回调函数。
同步和异步指的是对于消息结果的获取是客户端主动获取还是由服务端推送的。
阻塞和非阻塞
阻塞和非阻塞通常指的是针对IO的读写操作,如网络IO和磁盘IO等。那么什么是阻塞和非阻塞呢?简单地说就是我们调用了一个函数之后,在等待这个函数返回结果之前,当前的线程是处于挂起状态还是运行状态。如果是挂起状态,就意味着当前线程什么都不能干,就等着获取结果,这就叫同步阻塞;如果是运行状态,就意味当前线程是可以的继续处理其他任务,但要时不时地去看下是否有结果了,这就是同步非阻塞。
阻塞和非阻塞指的是客户端等待消息处理时本身的状态(是挂起的还是继续运行的)。
设计原理
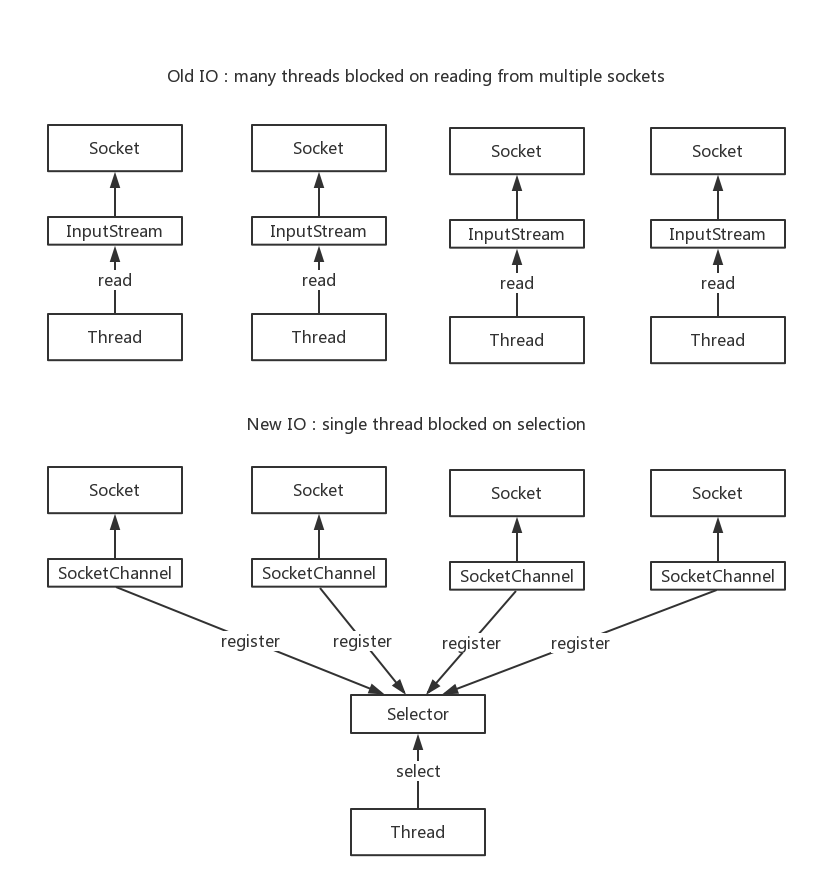
BIO设计原理
服务器通过一个Acceptor线程负责监听客户端请求和为每个客户端创建一个新的线程进行链路处理,典型的一请求一应答模式,若客户端数量增多,频繁地创建和销毁线程会给服务器带来很大的压力,后改良为采用线程池的方式来减少线程创建和回收的成本,被称为伪异步IO。
BIO模型之所以需要多线程,主要原因在于socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理IO的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里,但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质:(1)利用多核;(2)当IO阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
1 | 4j |
NIO设计原理
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以把它记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(Channel)继续进行读写。
NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询(selector.select())是阻塞的(没有可干的事情必须要阻塞),剩余的IO操作都是纯CPU操作,没有必要开启多线程。
客户端和服务器之间通过Channel通信,NIO可以在Channel进行读写操作,这些Channel都会被注册在Selector多路复用器上,Selector通过一个线程不停地轮询这些Channel,找出已经准备就绪的Channel执行IO操作。NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
1 | 4j |
NIO和BIO的区别
- 面向流和面向缓冲区
- BIO是面向流的,面向流意味着每次从流中读一个或多个字节直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
- NIO是面向缓冲区的,这有些细微差异。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。当然,在使用数据前,我们仍然需要检查该缓冲区中是否包含我们需要处理的所有数据。另外,需要确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
- 阻塞和非阻塞IO
- BIO的各种流是阻塞的,这意味着,当一个线程调用 read() 或 write() 方法时,该线程被阻塞,直到读取到数据或者数据完全写入,在此期间,该线程不能做其他任何事情。
- NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变得可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。在非阻塞模式下,线程通常将在IO调用中未被阻塞的空闲时间用于在其它通道上执行IO操作,也就是说,一个线程现在可以管理多个输入和输出通道。
NIO核心组件
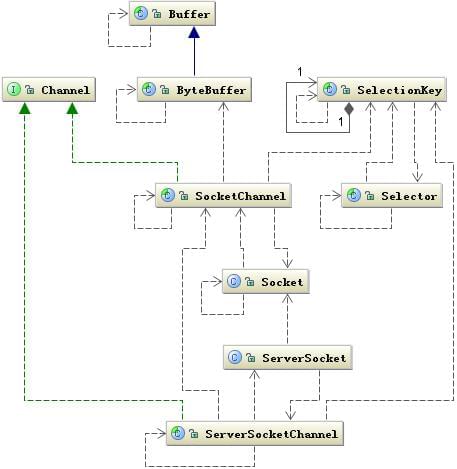
Buffer
在NIO中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;在写入数据时,它也是写入到缓冲区中的。任何时候访问NIO中的数据,都是将它放到缓冲区中。而在面向流IO系统中,所有数据都是直接写入或者直接将数据读取到Stream对象中。
Buffer缓冲区对象本质上是一个数组,但它其实是一个特殊的数组,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况,当我们使用 get() 方法从缓冲区获取数据
或者使用 put() 方法把数据写入缓冲区时,都会引起缓冲区状态的变化。
Buffer的几个重要属性
- position:指定了下一个将要被写入或者读取的元素索引,它的值由 get()/put() 方法自动更新,在新创建一个 Buffer 对象时,position 被初始化为0。
- limit:缓冲区数组中不可操作的下一个元素的位置
- capacity:缓冲区数组的总长度
- mark:用于记录当前 position 的前一个位置
属性值之间的关系:mark <= position <= limit <= capacity
1 | public final Buffer clear() { |
Buffer的基本用法
利用Buffer读写数据,通常遵循四个步骤:
- 把数据写入buffer
- 调用buffer.flip()
- 从buffer中读取数据
- 调用buffer.clear()或者buffer.compact()
当写入数据到buffer中时,buffer会记录已经写入的数据大小。当需要读数据时,通过flip()方法把buffer从写模式调整为读模式;在读模式下,可以读取所有已经写入的数据。当读取完数据后,需要清空buffer,以满足后续写入操作。清空buffer有两种方式:调用clear()或compact()方法。clear会清空整个buffer,compact则只清空已读取的数据,未被读取的数据会被移动到buffer的开始位置,写入位置则近跟着未读数据之后。
缓冲区的分配
在创建一个缓冲区对象时,会调用静态方法 allocate() 来指定缓冲区的容量,其实调用 allocate() 相当于创建了一个指定大小的数组,并把它包装为缓冲区对象,我们也可以直接将一个现有的数组包装为缓冲区对象。
1 | ByteBuffer buffer = ByteBuffer.allocate(1024); |
在HTTP协议中,通过请求头
Content-Length规定了发送给接收方的消息主体的大小,服务端可通过该值来进行缓冲区大小的分配,以防止缓冲区分配过大而浪费或分配过小而导致消息内容丢失。
- 缓冲区分片
1 | public class BufferSlice { |
- 只读缓冲区
1 | public class ReadOnlyBuffer { |
- 直接缓冲区
1 | public class DirectBuffer { |
- 内存映射文件
1 | public class MappedBuffer { |
NIO采用内存映射文件的方式来处理输入输出,NIO将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样访问文件了。
Channel
标准的IO编程接口是面向字节流和字符流的,而NIO是面向通道和缓冲区的。通常来说NIO中的所有IO都是从Channel开始的,数据总是从Channel读到Buffer中或者从Buffer写到Channel。
Channel和传统IO中的Stream非常相似,虽然很相似,但是有很大的区别:
- Channel是双向的(通道可以读也可以写),而Stream只能进行单向操作(只能读或者写),比如InputStream只能进行读取操作,OutputStream只能进行写操作
- 通道总是基于缓冲区Buffer来读写
- 通道可以异步读写
NIO中几个常用的Channel实现类:
- 基于网络操作:ServerSocketChannel、SocketChannel、DatagramChannel
- 基于磁盘操作:FileChannel
FileChannel用于文件的数据读写,它只能在阻塞模式下运行,不可以设置为非阻塞模式。
ServerSocketChannel允许我们监听TCP连接请求,每个请求会创建会一个SocketChannel,SocketChannel用于TCP的数据读写,DatagramChannel用于UDP的数据读写。
Selector
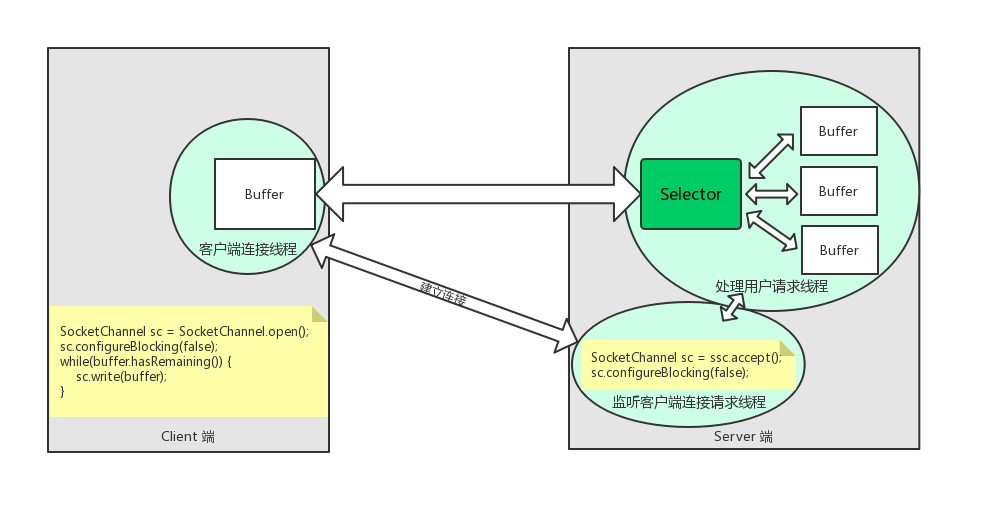
Selector能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,还避免了多线程之间的上下文切换导致的开销。
与Selector有关的一个关键类是SelectionKey,一个SelectionKey表示一个到达的事件,这两个类构成了服务端处理业务的关键逻辑。
总结
BIO
一个客户端的连接意味着需要服务器启动一个线程来读取客户端请求中携带的IO操作,由于线程是JVM非常宝贵的系统资源,当线程膨胀后,系统的性能急剧下降,随着并发访问量的继续增大,系统会发生线程堆栈溢出,创建新线程失败等问题,并导致进程宕机或者僵死,最终导致不能对外服务。后改良为用线程池的方式代替新增线程,被称为伪异步IO。服务器端使用线程池来处理客户端发起的IO请求,虽然,可以避免产生大量的线程导致JVM内存溢出,但是,当一个线程调用 read() 或 write() 方法时会发生阻塞,这样,当新的连接请求过来时,会导致线程池中的阻塞队列满,客户端也会出现连接超时现象。NIO
NIO相比于BIO的优点在于,采用一种基于通道和缓存区的IO方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆的 DirectByteBuffer 对象作为这块内存的引用进行操作,避免了在 Java 堆和 Native 堆中来回复制数据,是一种同步非阻塞的IO模型。AIO
一种完全异步非阻塞的IO模型,JDK1.7版本推出的,是最理想最快速的IO解决方案。
如果你需要同时管理成千上万的连接,这些连接只发送少量数据,例如聊天服务器,用NIO来实现这个服务器是有优势的。类似的,如果你需要维持大量的连接,例如P2P网络,用单线程来管理这些连接也是有优势的。如果连接数不是很多,但是每个连接的占用较大带宽,每次都要发送大量数据,那么使用传统的IO设计服务器可能是最好的选择。
